|
|
Character Fonts |
|
 |
|
You can include the character fonts
required for an application by downloading the attached files and use the LIB
command to store them
in memory. You can setup your system to process text as single byte, 2 byte
UNICODE or multibyte UTF8. See the LIB command for installing fonts. System
fonts ASCII8,ASCII16 and ASCII32 are built in. The wide rounded fonts are
preferred for higher quality designs.
Default font for text style is ASCII16 - v47.12.
It is possible to overlay one font over another to enable single byte operation
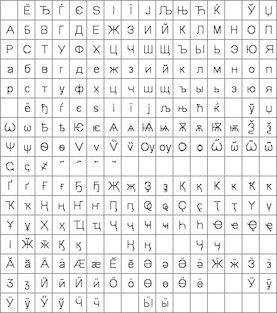
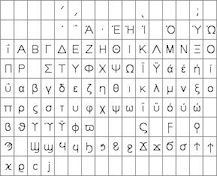
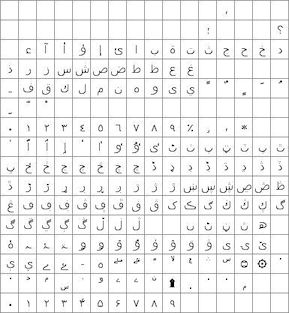
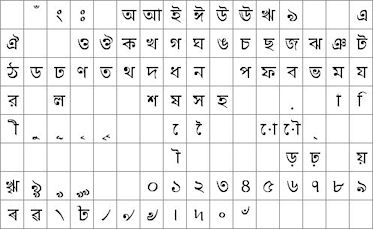
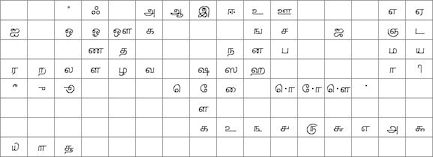
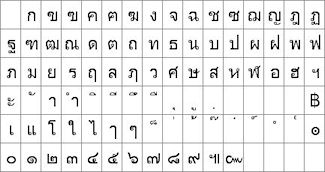
with ASCII from 20H to 7FH and Cyrillic, Greek, Hebrew, Bengali, Tamil, Thai or
Katakana from 80H to FFH. The LIB command is used to load the extended font at
0080H instead of it's normal UNICODE location. The style for a text can then
specify font="MyASCII,MyThai"; causing the Thai to overlap the ASCII from 80H to
FFH
Example:
LIB(
ascii24,”sdhc/asc_24.fnt”);
//upload ascii 24 pixel wide font
LIB( cur24,”sdhc/cur_24.fnt?start=\\0080”);
//upload currency font to 80H
In text style…
font=”ascii24,cur24”; //cur24 overlays ascii24 at 80H-8FH
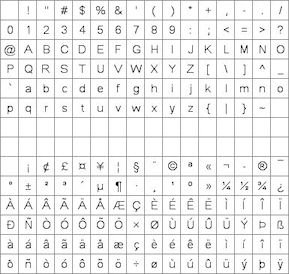
STANDARD ASCII - 20H to 7FH
Standard ASCII text in the range 20H to 7FH can by directly typed from the
keyboard.
System
fonts named ASCII8, ASCII16, ASCII32 are pre-installed.
Example
TEXT( txt1, "Hello World", stTXT ); //single byte access to
20H to 7FH ASCII characters
EXTENDED ASCII - 20H to FFH
2/
When using single byte ASCII in the range 20H to 7FH, you can access extended
characters from 80H to FFH using hex code like \\AB
Example
TEXT( txt1, "1. AB\\B0CDEF \\AB
s", stTXT );
//single byte access to 80H to FFH
UNICODE and UTF8
3/
When using single byte ASCII in the range 20H to 7FH, you can access UNICODE
characters by using hex code like
\\w0D7F
or a UTF8 character using hex code like \\mC2AB.
The symbols <....> are used where more than one character is coded.
Examples:
TEXT( txt2, "2. AB\\w00B0CDEF \\w00AB",
stTXT );
// UNICODE double byte access to 0080H to FFFFH
TEXT( txt3, "3. AB\\mC2B0CDEF \\mC2AB",
stTXT );
// UTF8 multi byte access to 80H to FFFFH
TEXT( txt5, "5. AB\\sB0C\\w<00440045>F
\\w00AB", stTXT ); // <....> are
used for long hex strings \\s is used for single byte in
a UNICODE or UTF8 encoded system
TEXT( txt7, "\\<372E204142B04344454620AB>",
stTXT ); // string
of single byte hex in the range 20H to 80H
TEXT( txt8, "\\w<0038002e00200041004200B00043004400450046002000AB>",
stTXT );
TEXT(
txt9, "\\m<392E204142C2B04344454620C2AB>", stTXT );
|
COMPACT NARROW FONTS
(Single Byte Range 20H to FFH or UNICODE Range 0020H to 00FFH)
The ASCII base page is included automatically at 20H-7FH and the other fonts are
automatically loaded to 80H to FFH.
This gives a single byte range of 20H to FFH.
|
|
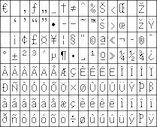
ASCII Base Page (96 characters) |
PC437 (128 characters)
|
PC850 (128 characters) |
|

5x7 8x16 16x32 |
 |
 |
|
5x7 8x16 16x32 |
5x7 8x16 16x32 |
|
|
|
|
PC852 (128 characters) |
PC858 (128 characters) |
PC860 (128 characters) |
|
 |
 |
 |
|
5x7 8x16 16x32 |
5x7 8x16 16x32 |
5x7 8x16 16x32 |
|
|
|
|
PC863 (128 characters) |
PC865 (128 characters) |
PC866 (128 characters) |
|
 |
 |
 |
|
5x7 8x16 16x32 |
5x7 8x16 16x32 |
5x7 8x16 16x32 |
|
|
|
|
WPC1252 (128 characters) |
Katakana (128 characters) |
|
|
 |
 |
|
|
5x7 8x16 16x32 |
5x7 8x16 16x32 |
|
|
WIDE ROUNDED Fonts
(Single Byte Range 20H to FFH or UNICODE Range 0020H to FFFFH)
When loading these fonts into library, it is
necessary to specify the offset address
for the first character of each
font table if a variation from UNICODE is required. The supplementary characters
above FFFF
are not supported in
UTF8. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
UPDATE INFORMATION
Version |
Title |
Date |
Details |
49.37 |
Fonts using too much memory |
10 Jun 13 |
|
Resolved issue where too much memory was being allocated for some fonts. This was only applicable to a small number of fonts which had a negative offset.
|
|
49.00 |
FONTS 90/270 Degrees |
22 Mar 12 |
|
Corruption of fonts when displayed at 90 and 270 degrees.
This was shown mainly in the built-in Ascii8 font, yet the problem existed with all font.
|
|
47.24 |
Font file - Fixed issue concerning storing of data when font table had gaps in. |
31 Oct 11 |
|
Fixed issue concerning storing of data when font table had gaps in.
* Fixed Unicode text in variables
|
|
47.12 |
Fonts - Default font for text style added: Ascii16. |
09 Sep 11 |
|
Default font for text style added: Ascii16
* Font entity also now checked for validity when text is drawn.
|
|
45.00 |
Font Loading - Font conversion where more data being processed than necessary. |
10 Jun 11 |
|
font conversion where more data being processed than necessary.
|
|
35.00 |
Fonts - Fixed scaled font character offset error. |
12 Nov 10 |
|
Fixed scaled font character offset error.
|
|
32.00 |
UNICODE / UTF8 FONTS 2+ Bytes - This version enables Unicode and UTF8 character coding for fonts. |
14 Oct 10 |
|
This version enables Unicode and UTF8 character coding for fonts.
From Friday 15th customers can download and use worldwide fonts
To define the default encoding for the system include the new �encode� parameter. Applies to .MNU menu files
SETUP(SYSTEM){ encode=val; }
> encode=s; // for single byte hex value (2 ASCII chars),
eg "Hello\\0AWorld" or "Hello\\32" (default)
> encode=w; // for wide hex value (4 ASCII chars),
eg "Hello\\2710" or "Hello\\000AWorld"
> encode=m; // for UTF-8 hex value (2*n chars),
eg "Hello\\C2B0" or "Hello\\0AWorld" or "\\E282AC"
To define the default encoding for the port include the new �encode� parameter
Applies for serial ports (ie RS2, RS4, AS1, AS2, DBG, I2C, SPI)
Text with hex embedded and raw hex are supported on ports.
SETUP(port){ encode=val; }
> encode=s; // for single byte hex value (2 ASCII chars),
eg "Hello\\0AWorld" or "Hello\\32" (default)
> encode=w; // for wide hex value (4 ASCII chars),
eg "Hello\\2710" or "Hello\\000AWorld"
> encode=m; // for UTF-8 hex value (2*n chars),
eg "Hello\\C2B0" or "Hello\\0AWorld" or "\\E282AC"
> encode=sr; // data is sent/received as 00h to FFh �raw� single bytes
> encode=wr; // data is sent/received as 0000 to FFFFh �raw� pairs of bytes,
most-significant first.
> encode=mr; // data is sent/received as 00h to FFFFFFh �raw� UTF-8
encoded bytes, most-significant first.
Over-ride Capability (Advanced rrequirements)
The encoding can be changed within a text string by using the \\ followed by the encoding type letter and multiple values can be changed by using the < and >, eg TEXT( txt1, "1. AB\\B0CDEF \\AB s", TXT );
TEXT( txt2, "2. AB\\w00B0CDEF \\w00AB", TXT );
TEXT( txt3, "3. AB\\mC2B0CDEF \\mC2AB", TXT );
TEXT( txt4, "4. AB\\w00B0C\\m<44>EF \\mC2AB", TXT );
TEXT( txt5, "5. AB\\sB0C\\w<00440045>F \\w00AB", TXT );
TEXT( txt6, "6. AB\\mC2B0C\\s<4445>F \\sAB", TXT );
TEXT( txt7, "\\<372E204142B04344454620AB>", TXT );
TEXT( txt8, "\\w<0038002e00200041004200B00043004400450046002000AB>", TXT );
TEXT( txt9, "\\m<392E204142C2B04344454620C2AB>", TXT );
|
|
25.00 |
EXTERNAL FONTS - All font/text functions rewritten to support 8-bit dithered fonts. |
03 Sep 10 |
|
All font/text functions rewritten to support 8-bit dithered fonts.
External font files (.fnt extension) can now be loaded using the LIB() command.
'?start' parameter added to library font load to allow specifying of font start address. If this is not specified, the Unicode value is used
Multiple fonts can be added to the text style, allowing character replacement and extending font tables: It is actually possible to mix a 16x16 and 32x32 font in the same text string�looks a bit crazy
STYLE( TextStyle1, TEXT )
{ font = FontName1; } // A single font does not need quotes
STYLE( TextStyle2, TEXT )
{ font = "FontName1, FontName2, ... FontName16"; } // Up to 16 fonts (multiple fonts must be enclosed in quotes)
Where multiple fonts are used, the last font is searched (FontName16 if present), then FontName15 (if present) is checked, etc. If the character is not present in any of the specified fonts, then no character drawn.
Except the special characters
\\0D (carriage return) which sets the cursor back to the start of the line
\\0A (line feed) which increments the line and sets the cursor to the start.
NOTE: only single characters in the range \\00 to \\FF are currently supported until the 2 byte Unicode is active. The demo includes 16x16, 24x24 and 32x32 ASCII fonts. The other fonts will be loaded on the website when 2byte Unicode is active.
|
|
|